Learning to Theorize the World from Observation
ICML 2026, Oral Presentation (Top 0.7% = 168/23,918)
Award: CompLearn 2026 Best Paper
Abstract
What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space, as in recent latent-dynamics and generative world-modeling work. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired.
Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations.
From Prediction to Theorization
Prediction asks what observation should come next. Theorization goes further by asking what mechanism produced the observed change. Getting the next observation right does not necessarily mean understanding the hidden rule that produced it.
L2T starts from minimal evidence: raw before-and-after observations. The learner is not told the program, the primitive operations, or which examples share the same rule. It only sees that one observation changed into another.
What Is Learning-to-Theorize?
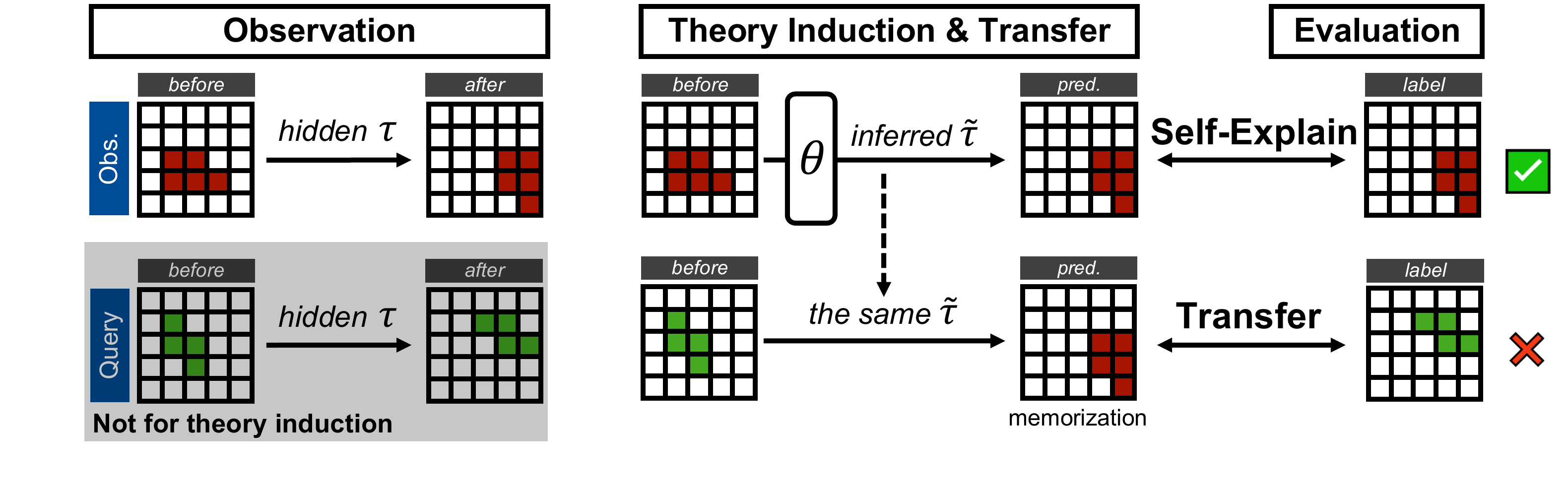
The basic unit is a phenomenon: a before-and-after observation pair \((x,y)\). The pair says that some hidden mechanism transforms \(x\) into \(y\), but not what the mechanism is:
Here, \(\tau\) is the latent theory, or program, that produced the phenomenon. A theory is an executable generative mechanism: it transforms a source observation into a target observation through a sequence of primitive operations.
Thus, in the L2T setting, understanding the world means inferring its underlying primitives and explaining observed changes as compositions of those primitives. A change such as “left-then-down” should be understood not as a single opaque event, but as a composition of reusable operations: “left” and “down.”
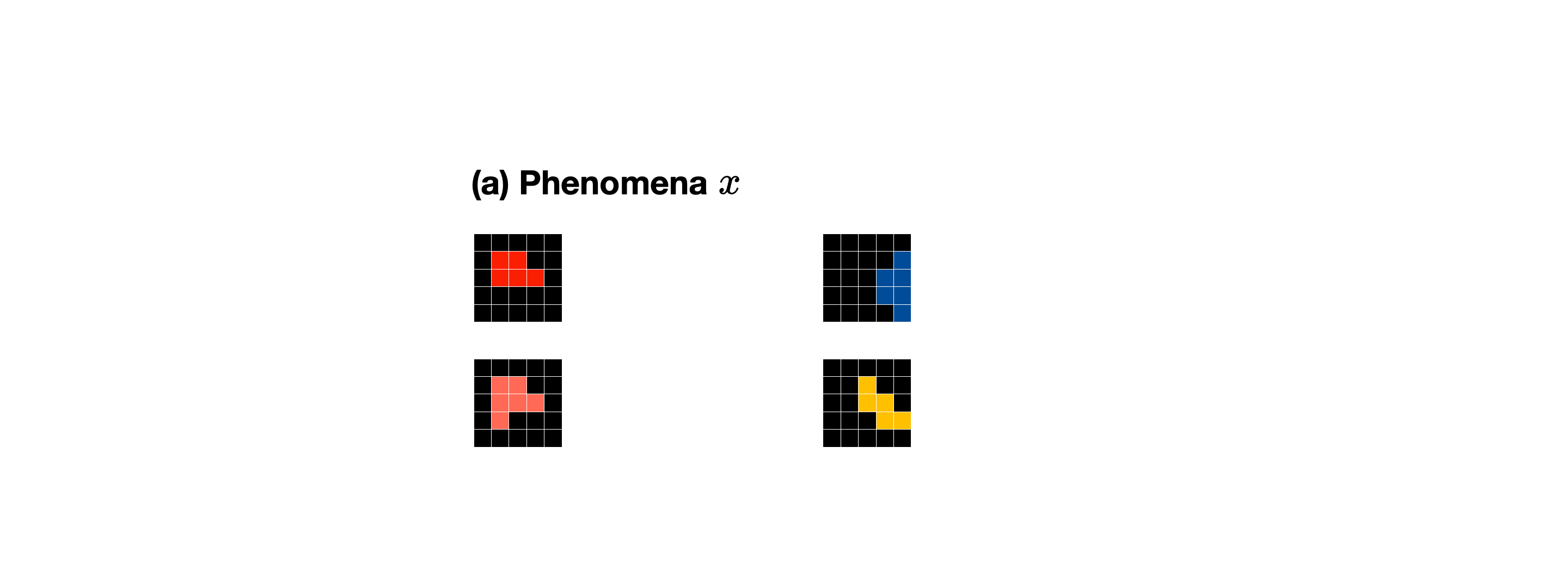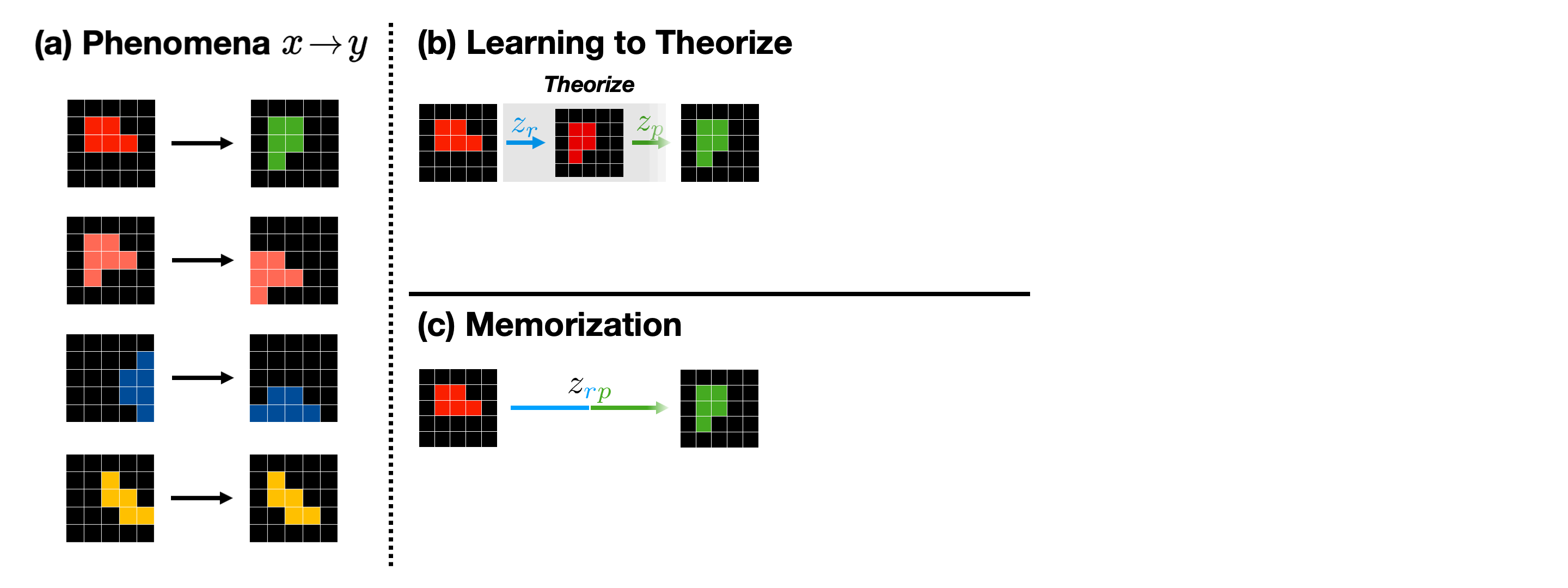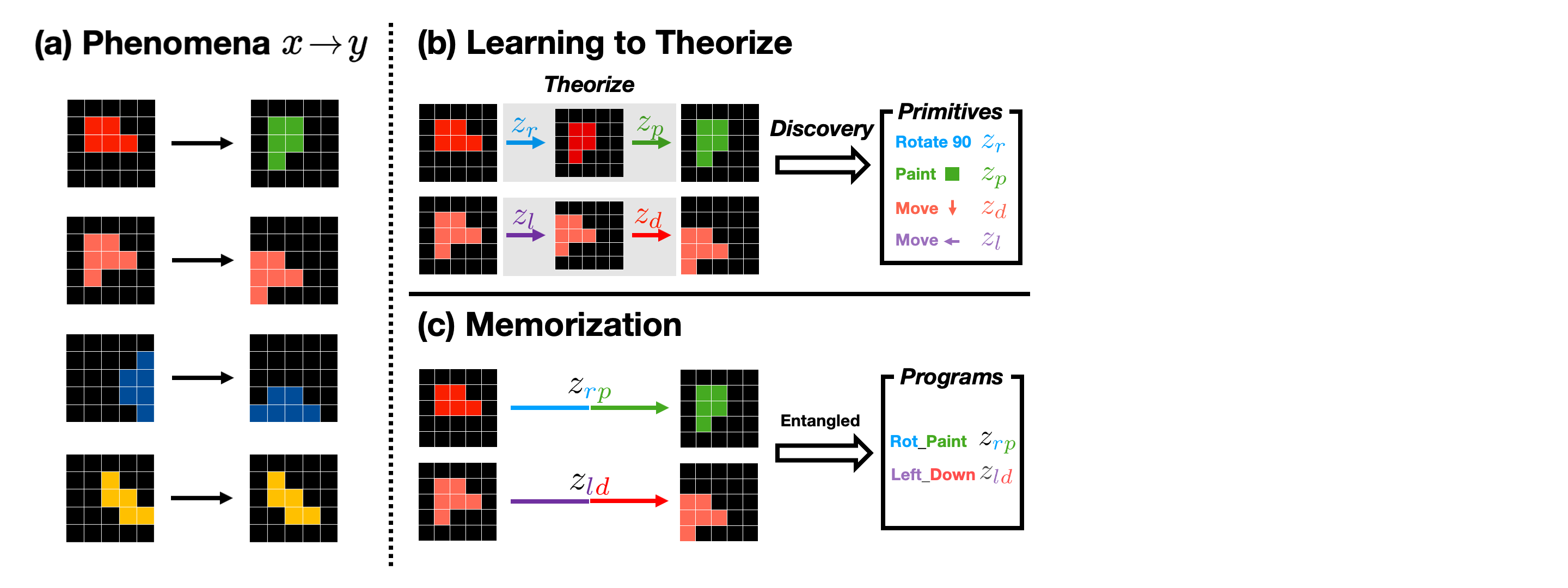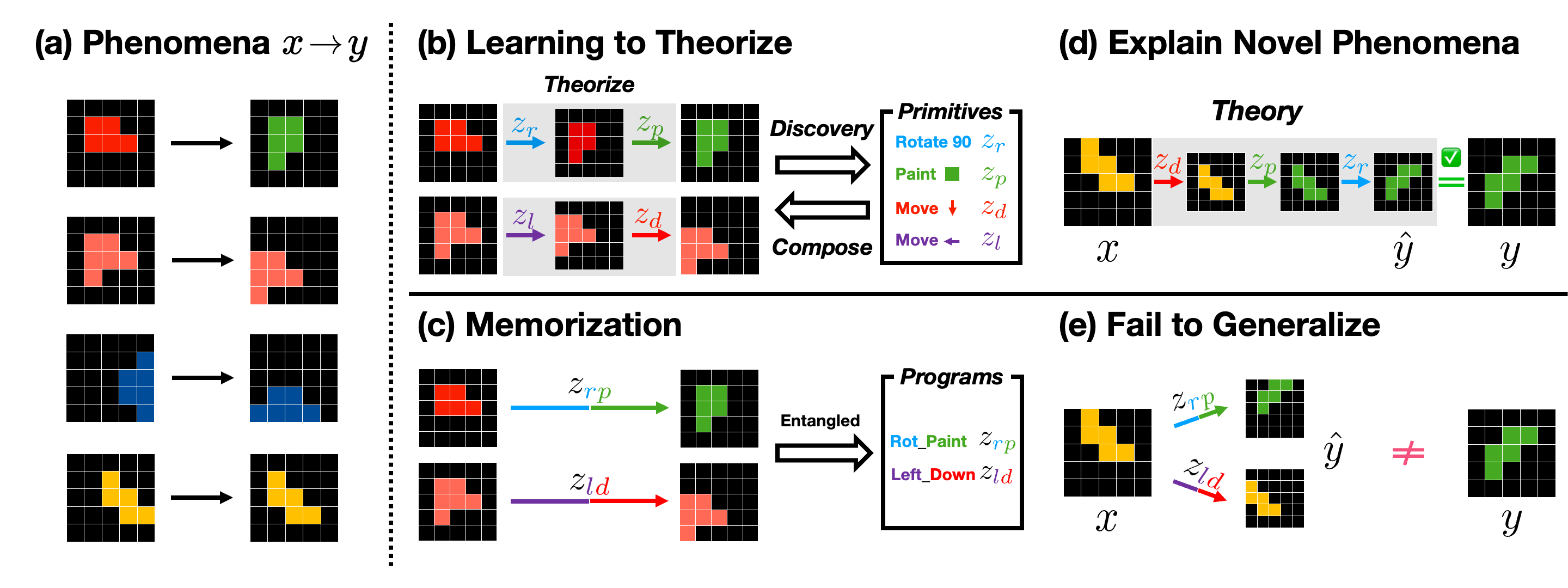
Reconstruction Is Not Enough
Reconstruction alone is not enough: a model can reproduce \(y\) without recovering the rule that produced the change. The decisive test is whether the inferred explanation transfers. From a support pair, the model infers a theory and executes the same theory on a new source observation:
If \(\hat{y}^{(2)}\) matches the true target \(y^{(2)}\), the model has captured a reusable generative rule. If it only explains the support pair, it has memorized an instance-specific shortcut.
Neural Theorizer
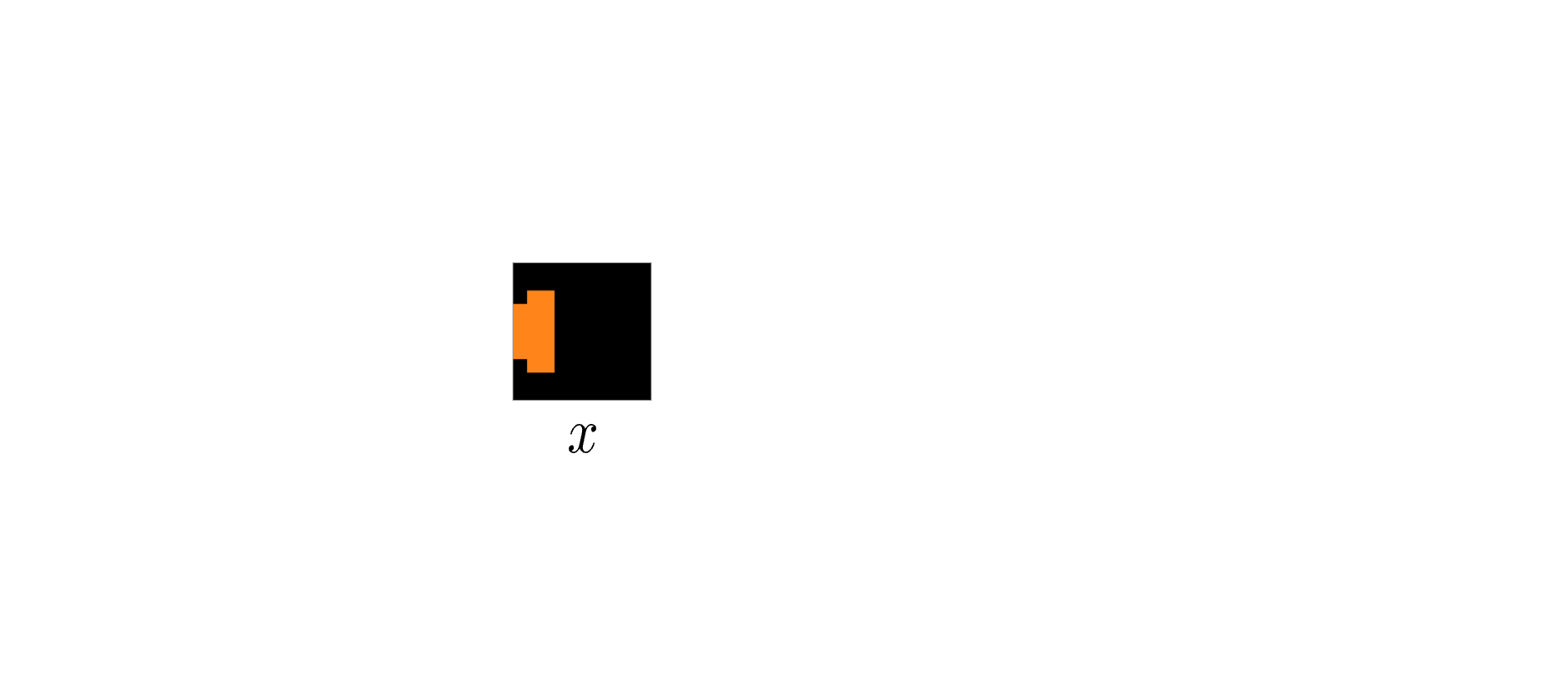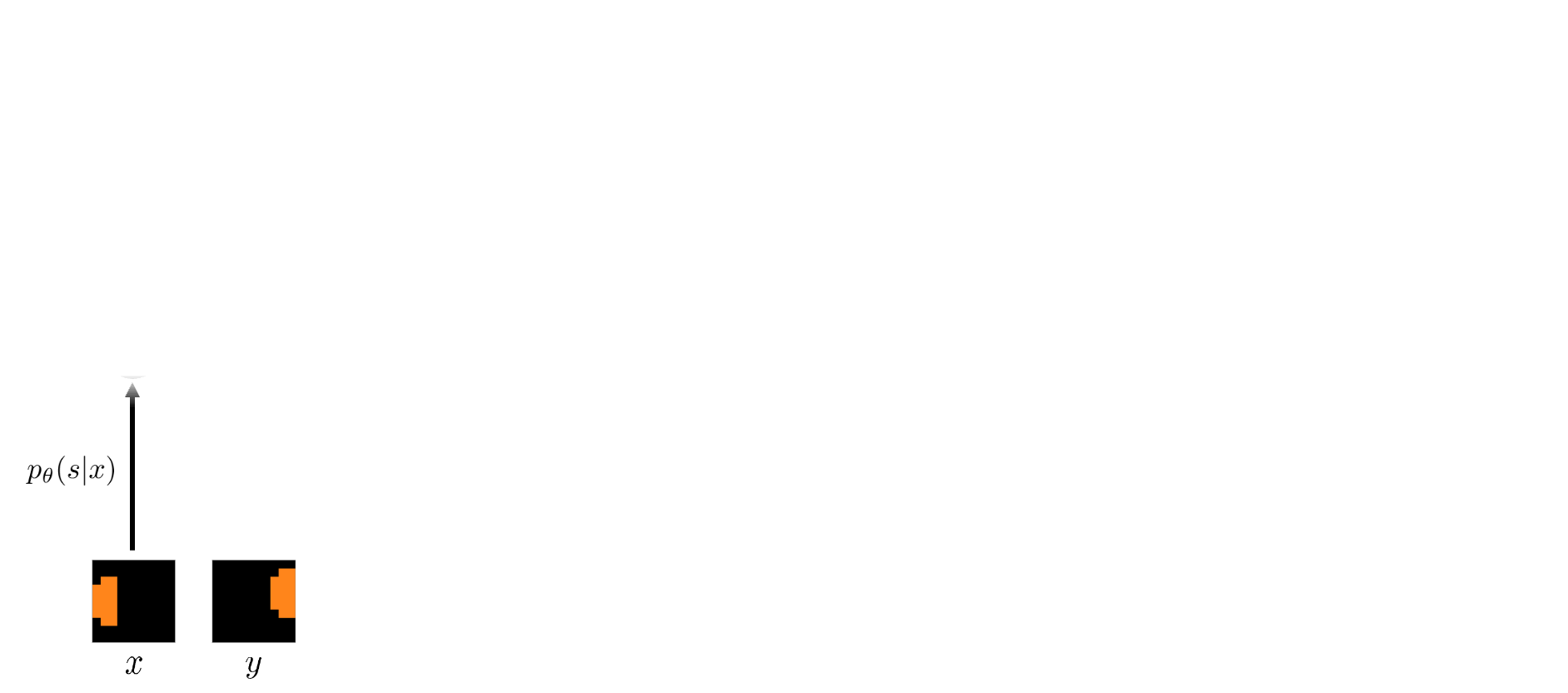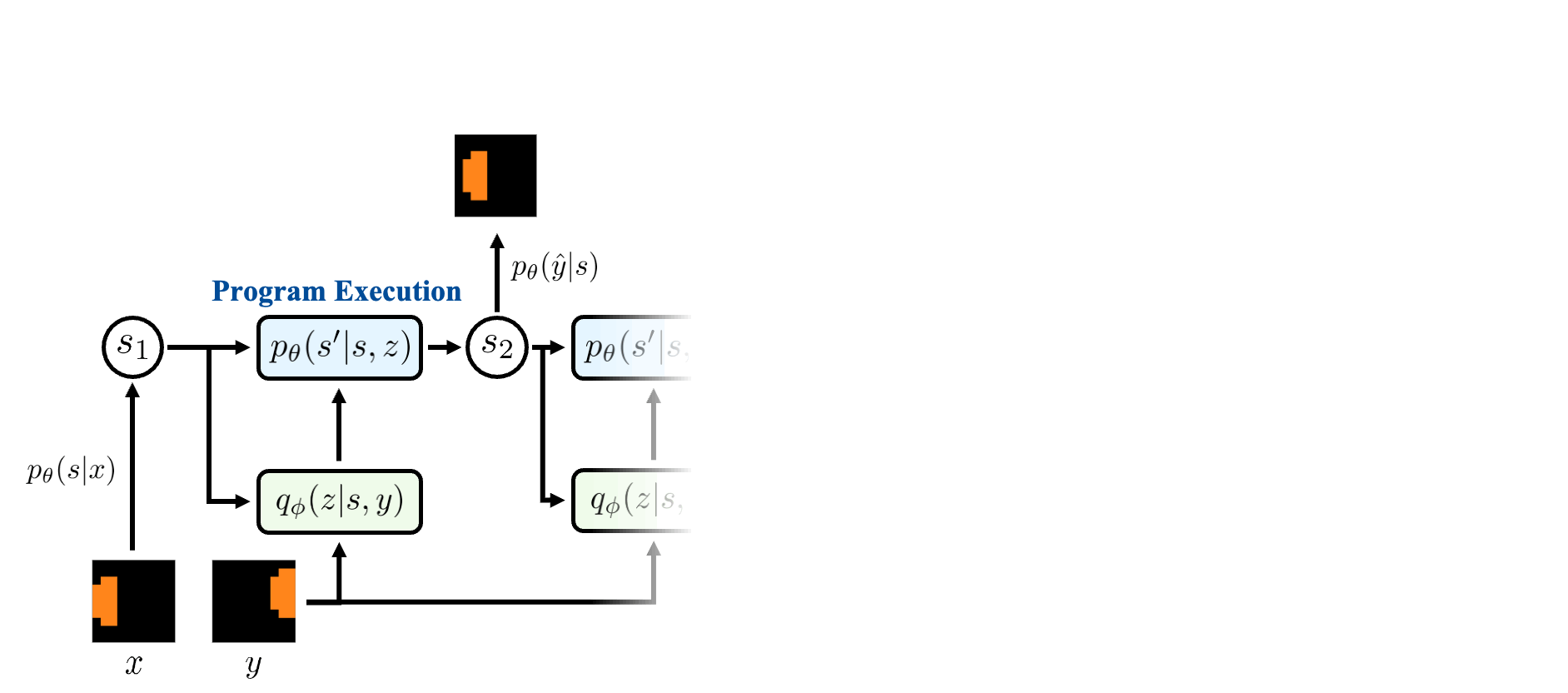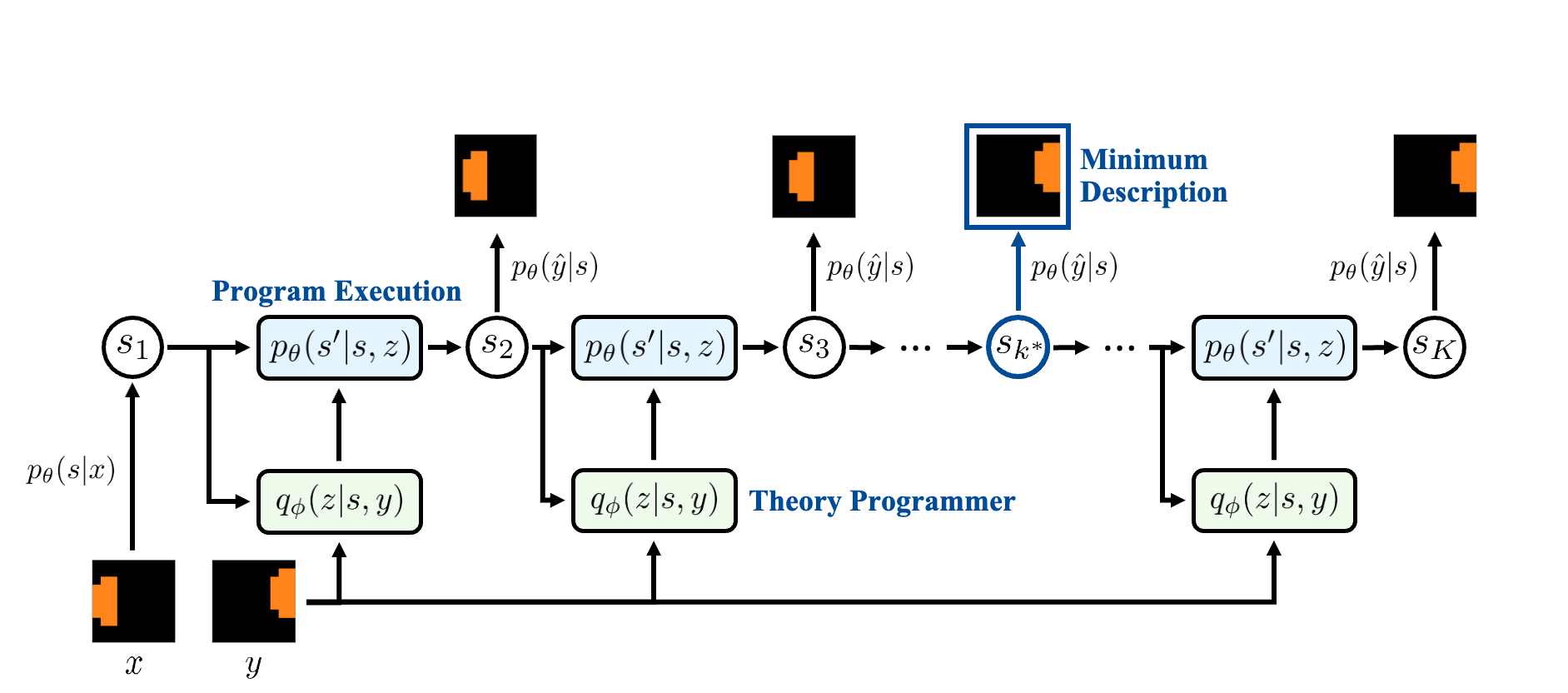
NEO implements L2T as latent program induction. It learns an internal vocabulary of primitive operations from raw observations and composes them into latent programs. The encoder maps an observation into a latent state, the programmer selects which learned primitive to apply next, and the executor applies it to produce the next state. An explanation is therefore a trace of learned operations rather than a single final representation.
Adaptive Explanation Length
The number of primitive steps should depend on the complexity of the phenomenon. NEO decodes intermediate states and selects the shortest accurate explanation:
where \(\lambda_{\text{MDL}}>1\) penalizes longer programs. This prevents simple changes from being forced into long explanations and discourages codes from becoming entangled composite transformations.
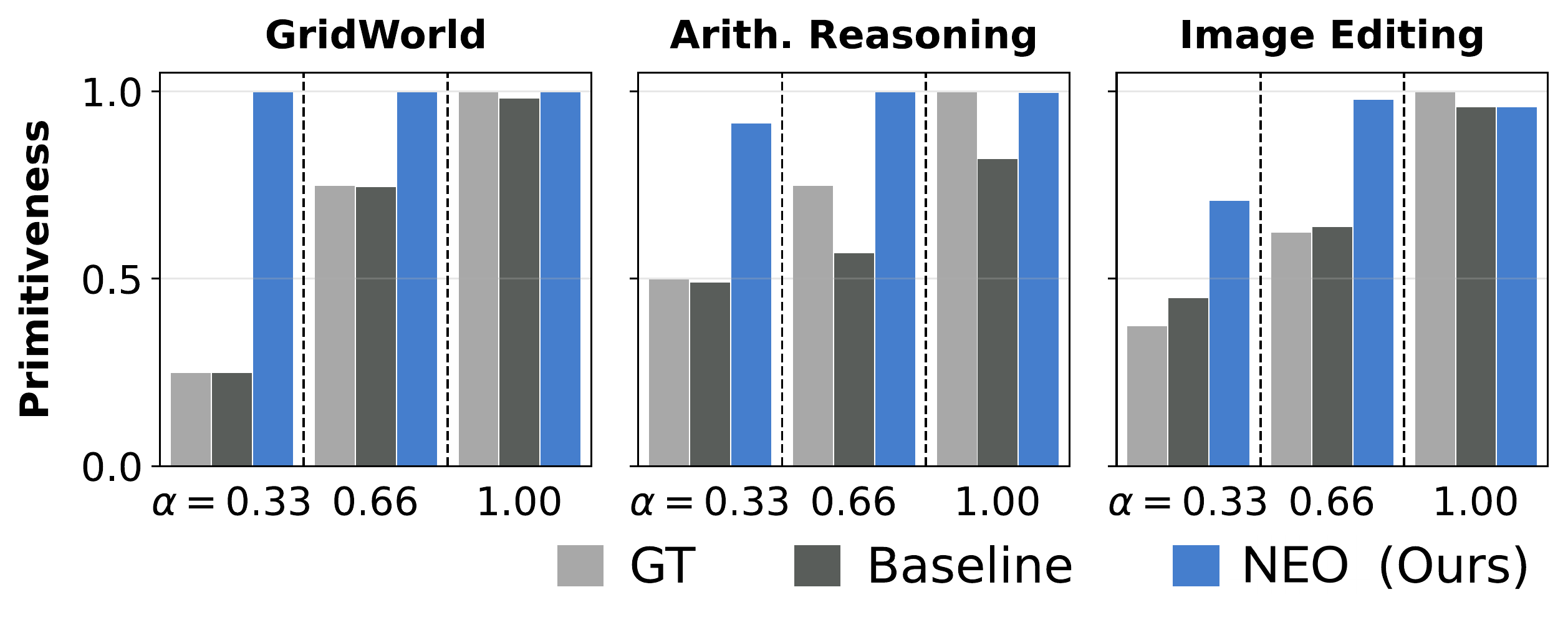
Observation-to-Theory Induction Benchmark
OTIB tests whether a model has learned theories, not only reconstructions. At evaluation time, the model receives a support transition, infers the latent theory, and executes that same theory on a query input.
The benchmark uses three domains to keep the notion of theory concrete: moving shapes in a grid, factorizing arithmetic transformations, and editing images. In all three, the hidden program is composed from a small set of primitives, but the learner sees only before-and-after observations.
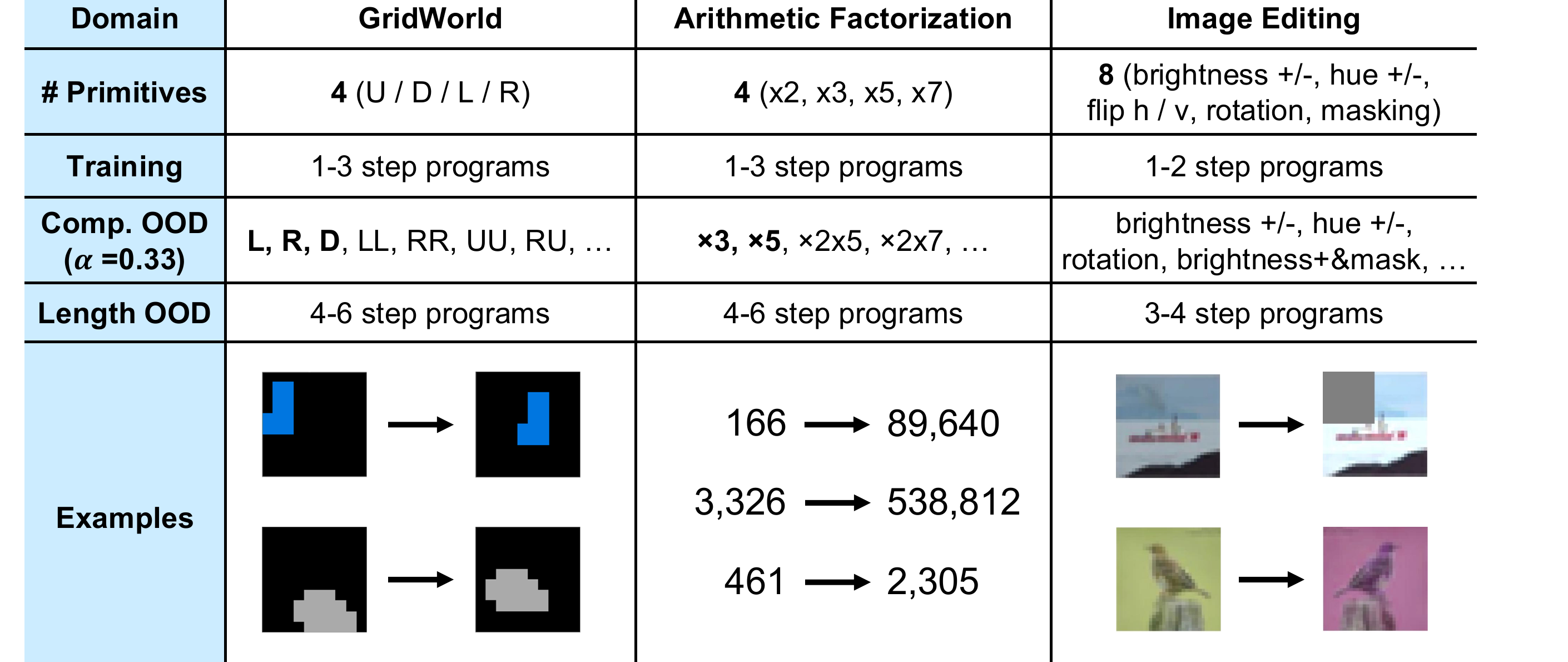
OTIB separates in-distribution, compositional OOD, and length OOD regimes. The parameter \(\alpha\in{0.33,0.66,1.00}\) controls how often short programs appear in training; smaller \(\alpha\) makes the setting harder because some primitives are never observed in isolation.
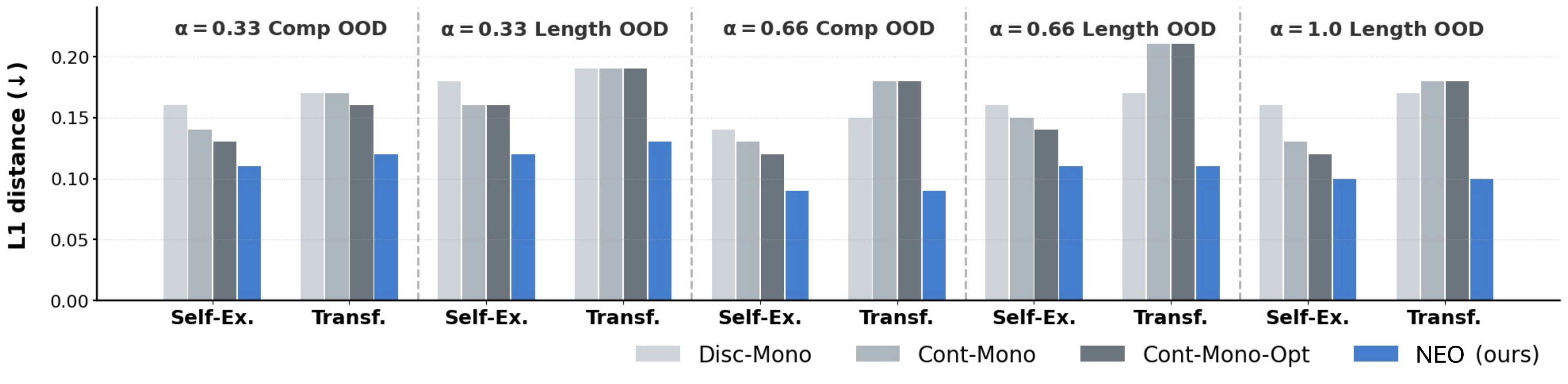
Transfer Beyond Observed Programs
Monolithic baselines fail in different ways. Continuous latent actions can reconstruct the support target but often do not transfer to a query input. Discrete monolithic actions transfer in-distribution, but they memorize observed composite actions and fail on compositional or length OOD splits. NEO improves OOD transfer by explaining each change as a sequence of learned primitives.
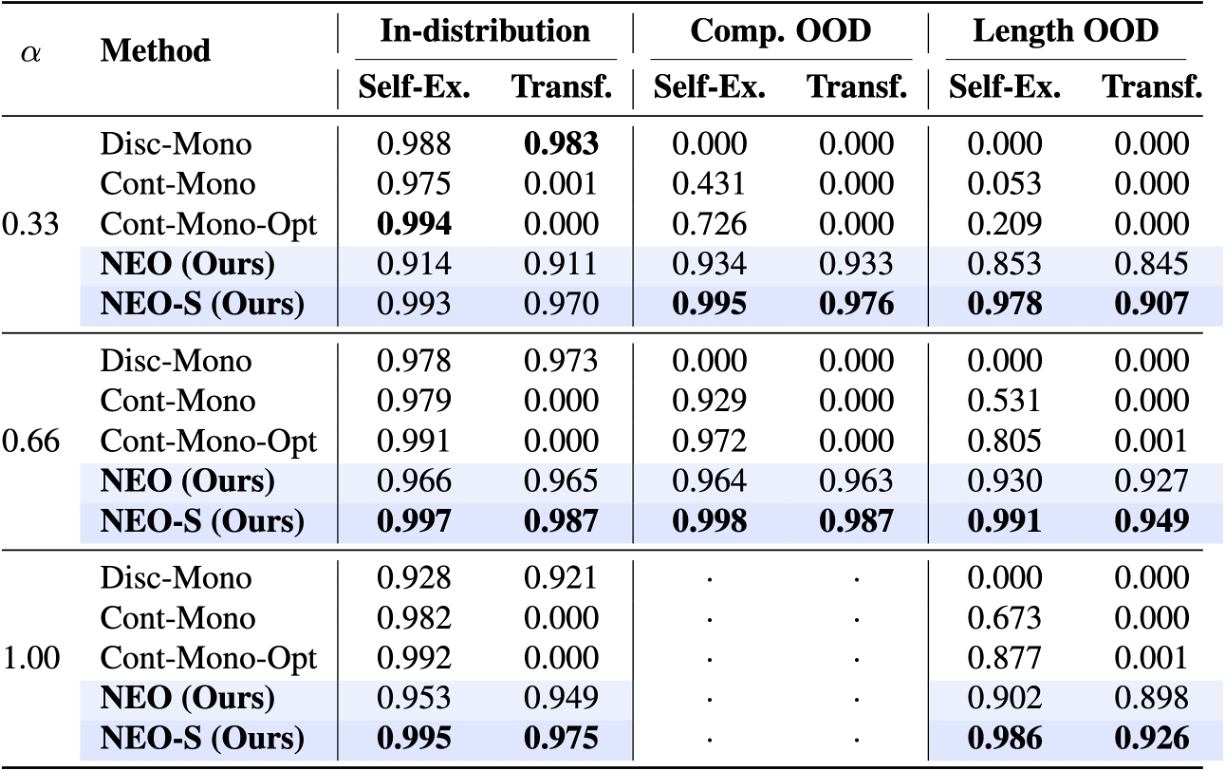
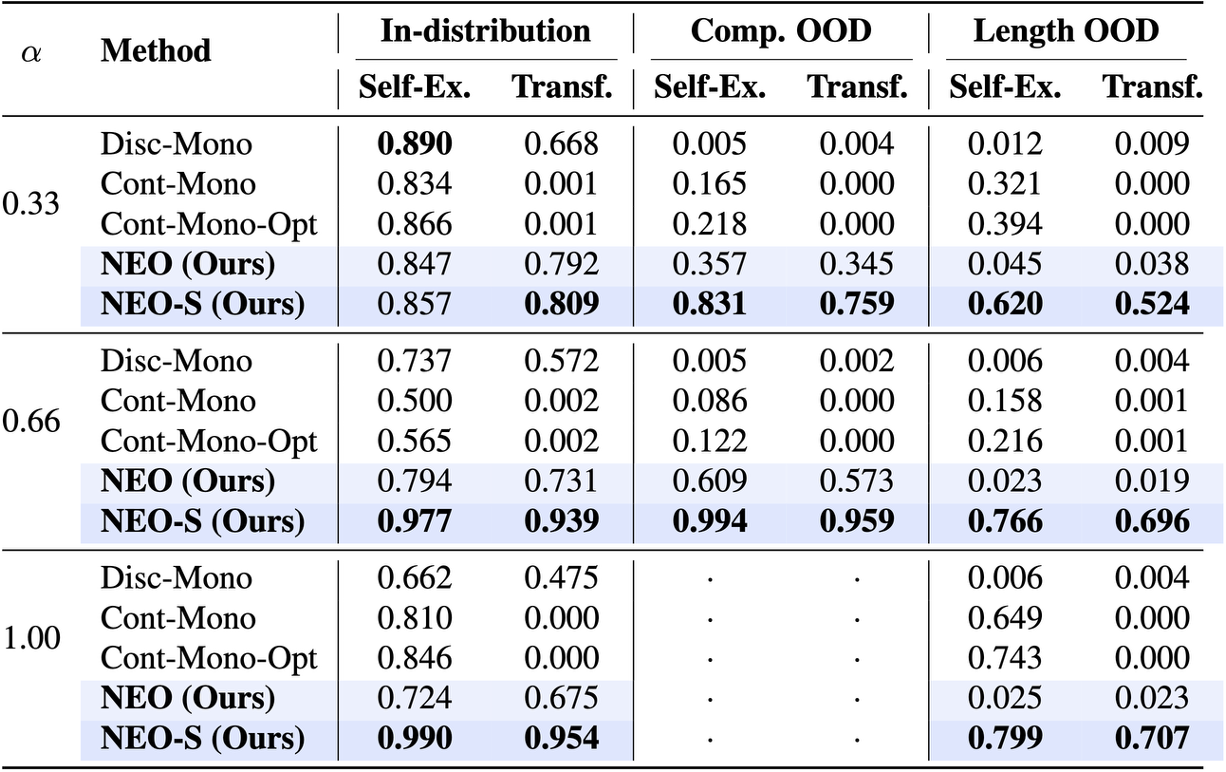
In both domains, high self-explainability does not guarantee transfer. The advantage appears when the model must recombine primitives into a program that was not observed as a whole.
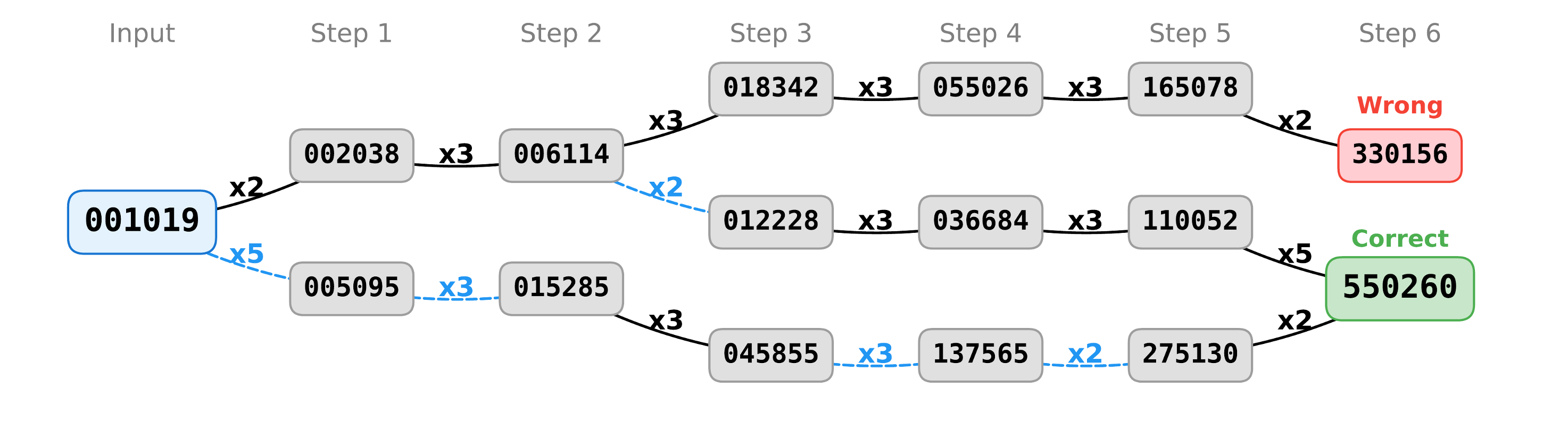
What the Learned Theories Look Like
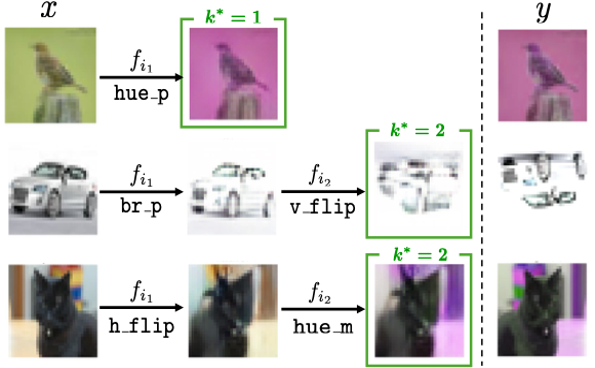
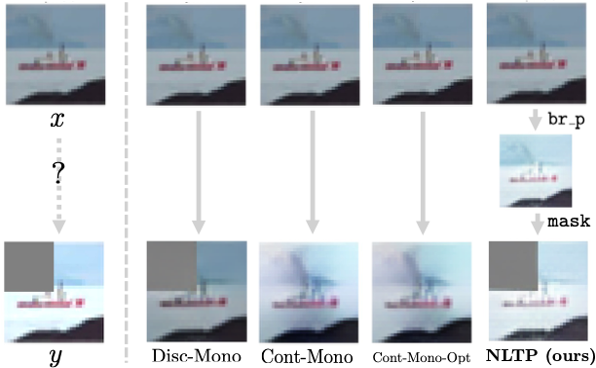
These visualizations reveal the form of the explanations learned by NEO. Rather than mapping a source directly to a target with a single latent action, NEO explains each change as a sequence of primitive edits. Simple changes terminate after one step, while compositional changes unfold as multi-step programs whose intermediate states remain meaningful.
Discovering the Units of Explanation
The key evidence is not only final accuracy, but whether the learned codes become useful units of explanation. Even some primitives are never observed in isolation; they only appear inside composite changes. NEO still recovers primitive-level codes, suggesting that it can discover the underlying operations needed to explain the world rather than merely memorize observed transformations.
Once the codebook behaves like a set of primitives, test-time search becomes meaningful. Sampling searches over alternative executable theories, not merely over independent reconstructions.
Takeaway
L2T reframes world modeling around explanation rather than prediction alone. NEO is a first proof of concept: it learns latent primitives without program supervision, composes them into executable theories, and transfers inferred programs to new inputs. The current setting is still controlled, with discrete primitives, short programs, and synthetic benchmarks. A natural next step is to study whether the same principle can scale to richer environments
BibTeX
@inproceedings{baek2026learning,
title = {Learning to Theorize the World from Observation},
author = {Baek, Doojin and Lee, Gyubin and Baek, Junyeob and Lee, Hosung and Ahn, Sungjin},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026}
}